賽後心得-「看見你的聲音--語音辨識後修正」
Last Update:
Word Count: 5.3k
Read Time: 18min
前言
決定命運的,不是偶然而是選擇。—電視劇 金裝律師 (Suits)
過往的失意,鬱結為一股不具名的悲傷,慢慢地,蛻變為養分。大學後我開始注重自己的選擇,追尋自己的意志,探索自己要的是什麼,結果是—迎來戲劇性的大學生涯。
雲霄飛車,一次次跌宕起伏,大學生涯亦然。突然發現自己喜愛資訊領域,進入後突然被抓去比賽,小有成就卻慘敗,進入一股低潮。莫名的,就站在舞台上,獲頒那夢寐以求的銅獎…替我曾經覺得遙不可及的奧匹資訊賽命題。
糊裡糊塗的倉促準備實習,進到我想進的公司 KKBOX。卻意外勾勒起落地又揚起的音符—「語音」與興致勃勃的我。於是隨性地訂下持續升學並研究語音辨識的目標。我想…很慶幸的,我並不是源自於對出社會的恐懼而升學,也並非背負家人的選擇而選擇,而是衷於我自己的想望,這是我最幸運的一件事。
去年十一月,推甄上台大資工所,並如願加入「多媒體資訊檢索實驗室」的語音組,此時的我像剛進入幼兒園,純真而好奇地探索每樣事物,懵懵懂懂地甚是純真,緩步地吸取新知。
我想,並沒有所謂的偶然,而是選擇決定了自己的命運吧!
緣起
實習、實驗室和課程,如此稀疏平常的生活一天天過去了。某天,兩位涉世未深的「碩 0 生」被指派參加玉山銀行舉辦的「看見你的聲音—語音辨識後修正」競賽,沒錯…其中一位就是我!
介紹
我們參加的是玉山銀行主辦的「看見你的聲音—語音辨識後修正」,看起來倒像綠豆糕,痾…不是!看起來很像「語音辨識」的主題,不過這塊領域長期是乏人問津,投入該領域的人並不多。事實上,他是「後修正」,意即做完語音辨識後,以「自然語言處理 (Natural Language Processing, NLP)」手法再進一步修正。
NLP 領域其實也並不多人,因此該比賽在 T-brain 平台上是最少人參與的,即便如此,仍有一百一十九隊參加!
銀行業近年來盛行導入智慧 AI 機器人,而該場比賽情境也十分雷同。玉山 APP 提供智慧化的語音服務,服務接受使用者的聲音後,經過 ASR (Automatic Speech Recognition) 模型辨識,產生出前十可能對應的語句—這些都是前半段「語音辨識」所屬的範疇。
賽事所做的就是後半段的「語音後修正」,依據語音辨識的結果,可利用不同候選句之間的關聯再次糾正,即為本次賽事的主要任務,不過…當然不僅如此而已,比賽較像是要求我們提供「正式對外服務」,我們需要架設 API Server 對外提供服務…!
每筆 Request 即為可能語句列表、時間和重試次數等等,當服務接受需求後,必須在一秒內回傳一句結果。然而…要命的來了,同時可能有十筆 Requests 席捲而來!更何況是在日益肥大的 NLP 領域達成這樣的豐功偉業,也因此一度「人性化」地在賽中放寬至兩秒,但仍舊是個很浮誇的需求。
小小不幸
何謂不幸?身為涉世未深的碩 0 學生,在賽事開始後一個月才參賽,以一個狀況外的鄉巴佬姿態誕生,如同新手逛街打怪,遇見地獄大魔王一般。我與隊友更是第一次參加 AI 相關賽事,憑藉隊友曾是 NLP 的過客,配合我在實習鍛鍊的後端能力,組成一支全面性俱佳的隊伍—CUDAOutOfMemory。
敝隊駕馭的電腦配備兩張 GeForce GTX 1080 Ti,而在我們初次與其相見歡的剎那,Out Of Memory 纏身—就那樣…戲謔性地成為了隊名XD
NLP Model
綜觀比賽本身,可以注意到不僅後端需求相當高,以語句本身的 baseline 亦是相當傑出,約略為 9.34 % CER (Character Error Rate),這是經過玉山 ASR 辨識後的最佳結果。奠定在這基礎上,還想要更好的表現實屬不易,還得承受高強度的需求,只能說獲獎希望渺茫,藍瘦香菇啊……
我們選擇肥碩的 Transformers model,將「糾錯問題視為一種翻譯任務」展開一系列操作,添加額外文本 CLMAD、產生錯誤文本、困惑度 (Perplexity, PPL) 和 nlp-fluency。不幸地,在測試賽效果都十分有限。
零零總總的各方嘗試,於最終正式賽改進了 1 % 的 CER,成為唯一的 100% 使用 Supervised Learning 仍能獲獎的隊伍,真是萬幸啊XD
API Server
而我在這場比賽中,一肩扛起後端的重責。將這樣一個重大任務,交給一位初出茅廬,或許談不上是「後端工程師」的我來主掌,這隊也沒人才了…命在旦夕,得獎希望黯淡無光且渺茫啊…!
悵然若失、眼神空洞的….實驗室主機,一聲長嘆,然後一操再操。身為前六名中少數「超在意」後端的隊伍,也是少數從後端層面一次次加速,而達到賽事的要求,這也算是對實習一年來的成果驗收吧!
而接下來,就要面對一波波狀況,見招拆招了 :P
狀況一
想像一下,你在玩 Random Dice 這款骰子塔防遊戲。
身為左邊的玩家,你可愛的骰子們等級都太嫩,一隻敵人就應付不暇,更何況後面一條龍。是的,由於 NLP Model — Transformers 的肥大,依據推論高達 2300 ms,遠超過主辦方要求,一個應付不暇,更何況一次來十個?
那麼,就得先針對問題本身思考,盡可能去蕪存菁。候選句全部都很重要嗎?這是第一個問題。人眼掃描後,可以發現越後面的語句越荒謬,在應付不暇的狀況下,其實第一句就已經堪用,保留了許多最重要的資訊了。
接下來,就得思考「模型」真有需要那麼「深度」嗎?由於訓練資料寡寡可數,大概六萬筆稱不上是大資料,Model level 太深,或許還有過度擬合 (Overfitting) 的風險,故可將層級壓低些。
如此一來,服務進展到單筆 700 ms 的狀態,可說是一大里程碑。但你可要知道「一個打十個」是多麽剽悍的事實。
狀況二
面對十個敵人,全數解決僅花一秒鐘。顯然地,隨著敵人增加,打倒全部所需的時間勢必也會線性成長,這對於服務本身也是相同的狀況。
因此,可從幾個層面著手:
- 排程—Queue vs. Concurrent
- 設備—CPU vs. GPU
- 拒絕滿分—「想守住越多,失去的越多」
拒絕滿分這項,其實離我們都很近。上了高中,若抱持著題題斃命的心態,數學就會使你一槍斃命。因此在以某種策略挑選題目一個個解出,才能達到最佳表現。而在本次賽事中,已知語句列表是按照排行榜排序的,因此若無暇處理它,那就回傳最佳的語句,就是一種損失最少的方式。
當前處理程序的方式屬於 佇列 (Queue) 排隊式的,程序其實和交通很相似,雪隧一但遭遇事故,整條國五就會呈現紫色地獄。如果有多條道路疏通,那就太好了!在處理要求 (Request) 就會面臨類似的窘境,但若以 Concurrent 的方式,則會讓整體服務速率都降低,若整體速率高於一秒,就更淒慘了…一筆也完成不了。
以 Concurrent 方式處理要求,我們實驗了 WSGI, Nginx 等正式部署工具,最終以 Flask 內建的 Thread 效能最佳,與其他兩項工具效能相差近三成。
Flask Thread 事實上是利用「快速切換」,在多筆 Request 間流轉、輪替,達成近似於「同時」處理的效果,而非真正意義上的「同時」,這是 Python 本身語言上的限制所致。總而言之,暫時以這樣的方式,配合 奴役 GPU 1080 和這三大策略,順利獲得以下的回應效能。
拒絕滿分這項,其實離我們都很近。上了高中,若抱持著題題斃命的心態,數學就會使你一槍斃命。因此在以某種策略挑選題目一個個解出,才能達到最佳表現。而在本次賽事中,已知語句列表是按照排行榜排序的,因此若無暇處理它,那就回傳最佳的語句,就是一種損失最少的方式。
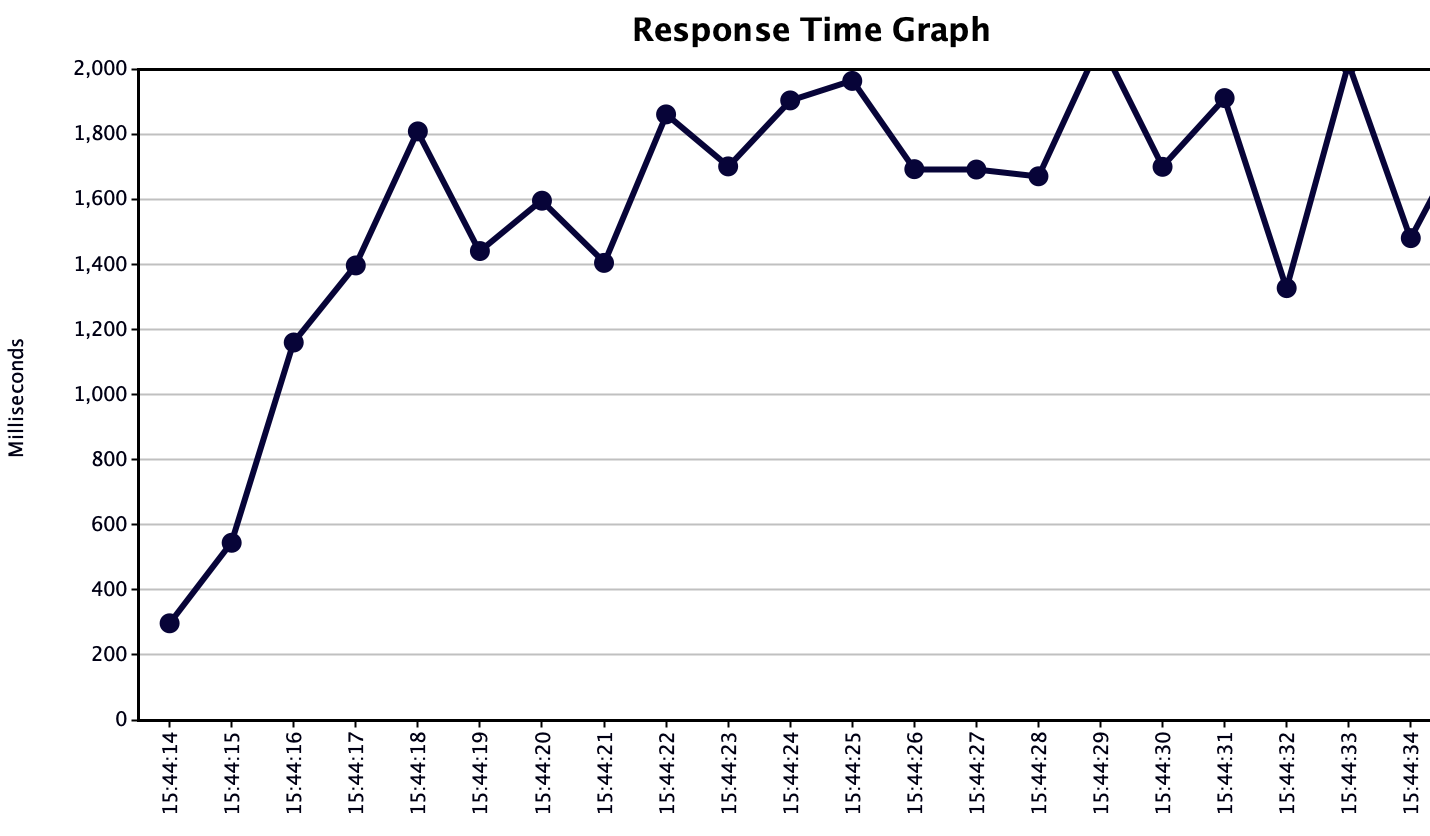
Response Time Graph 會記載「何時」收到的 Request,每筆 Request 間隔多久才回傳結果,可以很直觀地看到整體服務的狀況是否在時間內。很顯然地在上圖中隱隱約約不妙、悲劇溢於言表,多筆 Request 回應時間高於兩秒,這代表整體效能還是不夠快。
狀況三—Batch
同時處理大量需求,始終會因為「高速」輪替而犧牲掉變換的時間 (context switch),換個角度思考,是不是可以設定一個時間,在這段時間內盡可能搜集 request,時間到時一口氣同時處理,那麼配合 GPU 平行處理的威力,肯定能提高效能的吧!?
結果找到了這項工具 ShannonAI/service-streamer 完成了這項豐功偉業,Throughput 5.7 / sec 提升至 14.5 / sec,效率為原本的 254 % 之多。啊…斯巴拉西 (素晴らしい)!!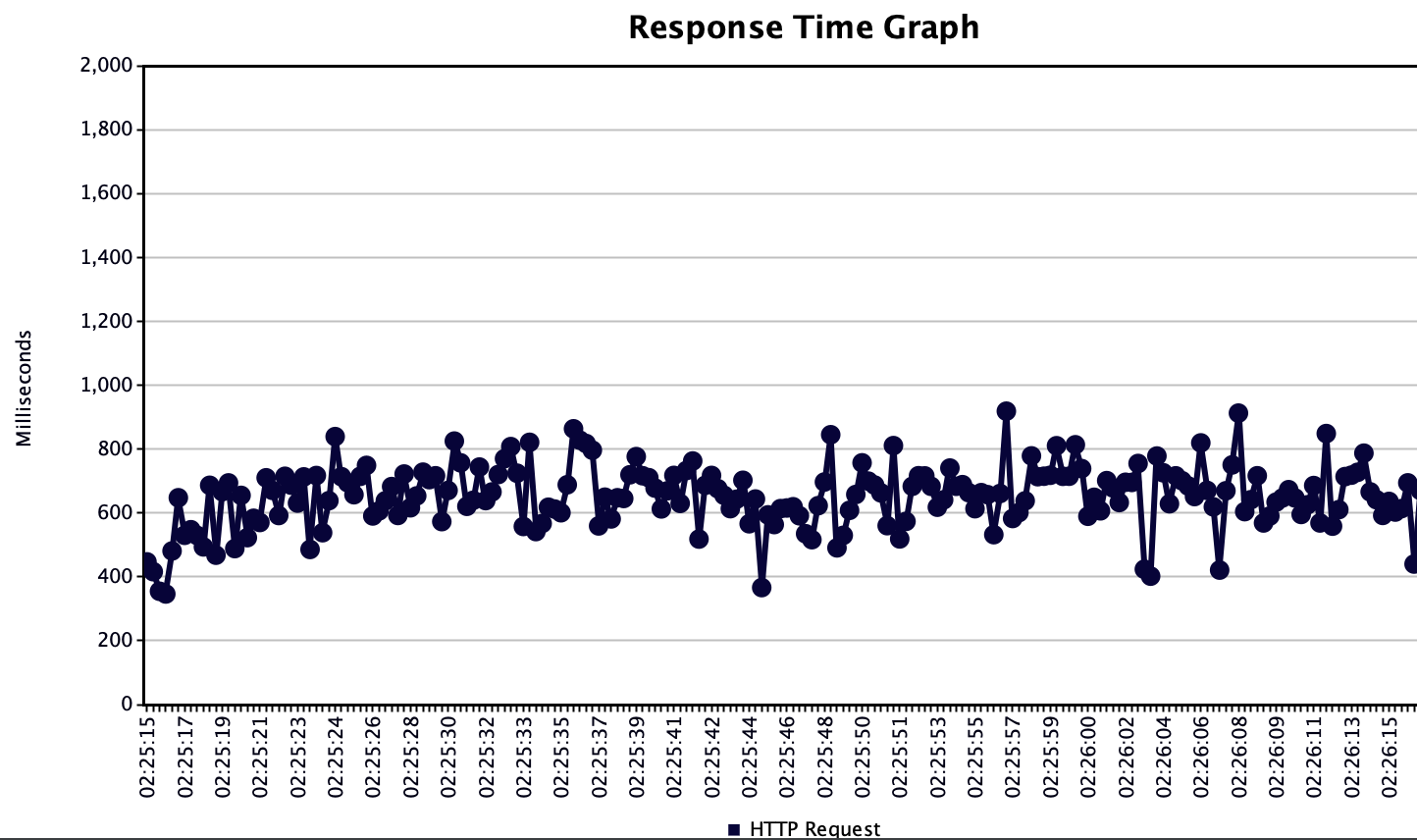
測試
速度到位了,就得進到測試,這是個博大精深的學問…
而我們用了三種方式一一去確認我們服務的運作、速率,以及在高壓狀態下是否能照常服務:
一項產品上線後能否正常維運,壓力測試是很重要的環節,而你要盡可能的「高壓」去欺凌你自己的服務,把自己當成「壞壞使用者」去設計一些奧客才會做的事在測試裡頭,長句、錯誤句等等,若服務能夠安然無恙的照常運作與輸出,那服務「可能」就沒問題了。
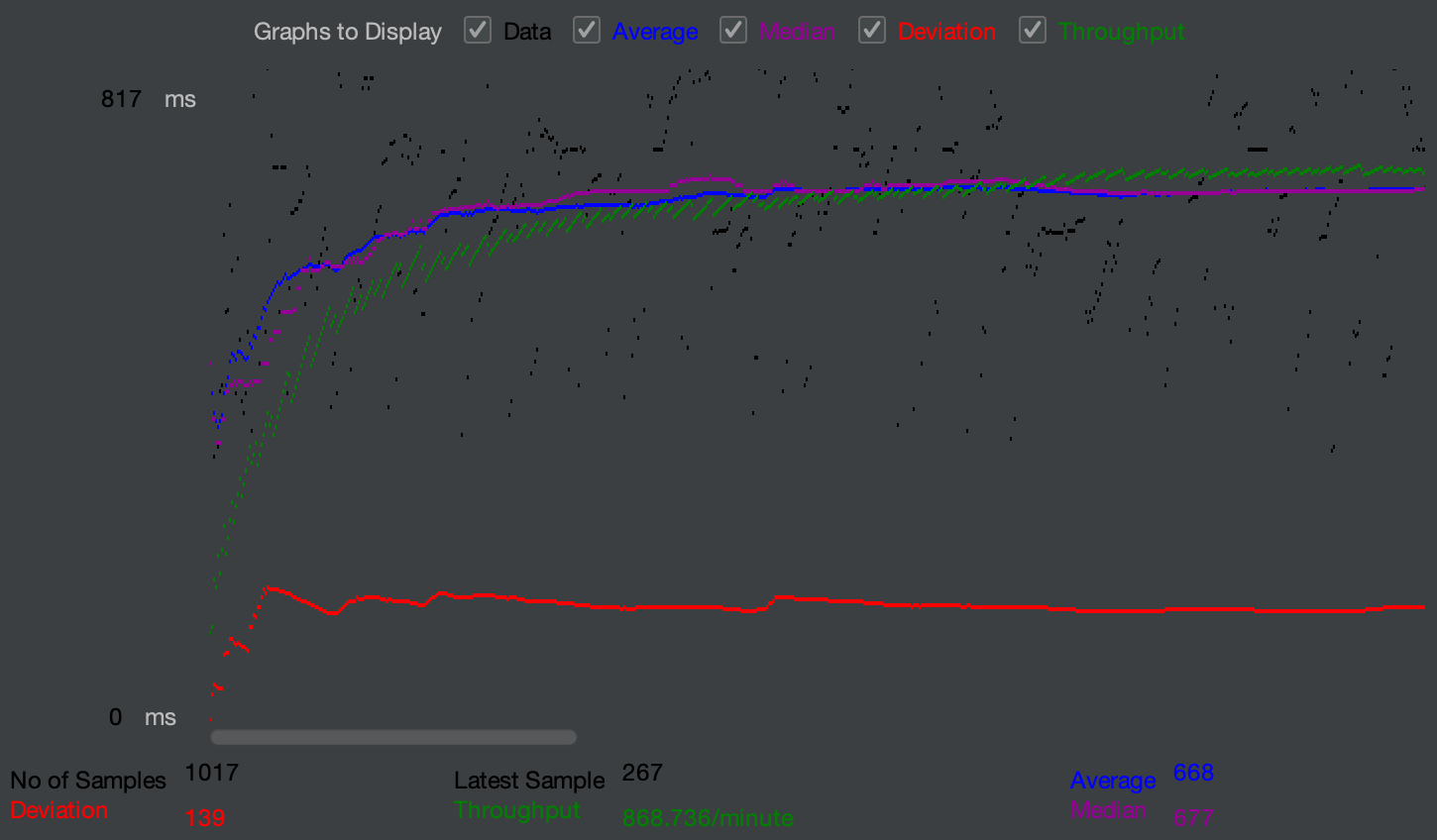
上圖為 JMeter 的測試曲線圖,這套工具是提供測試的開源軟體,能夠模擬多名使用者運用服務的承載狀況。而從圖中能注意到紅、綠和藍色等等不同的曲線:
- 流通量 (Throughput):每分鐘能處理的需求 (Request) 量。
- 平均時間 (Average):每筆需求處理的平均時間 (毫秒)。
- 中位時間 (Median):所有樣本 (sample) 按照處理時間排序後之中位數。
另外,可以設定「暖機」時間,在一個現實運作的服務中,流量也是逐步的上升與下降。我們可以仿照這樣的情境,設定幾秒後才達到最大用戶數,也因此綠色的流通量曲線並不是起初就維持高輸出,而是配合暖機時間逐步上升的。當然,JMeter 作為一個專業的測試工具,還有許多擬真情境的功能可以嘗試!這邊就不一一說明了。
總之!從這張圖中透露出服務能夠穩定的輸出某個定值,而單就當前的需求量而言,並不會影響到整體服務的效能,故能夠判定「可承受」比賽規格的服務需求。
架構圖
總之!從這張圖中透露出服務能夠穩定的輸出某個定值,而單就當前的需求量而言,並不會影響到整體服務的效能,故能夠判定「可承受」比賽規格的服務需求。
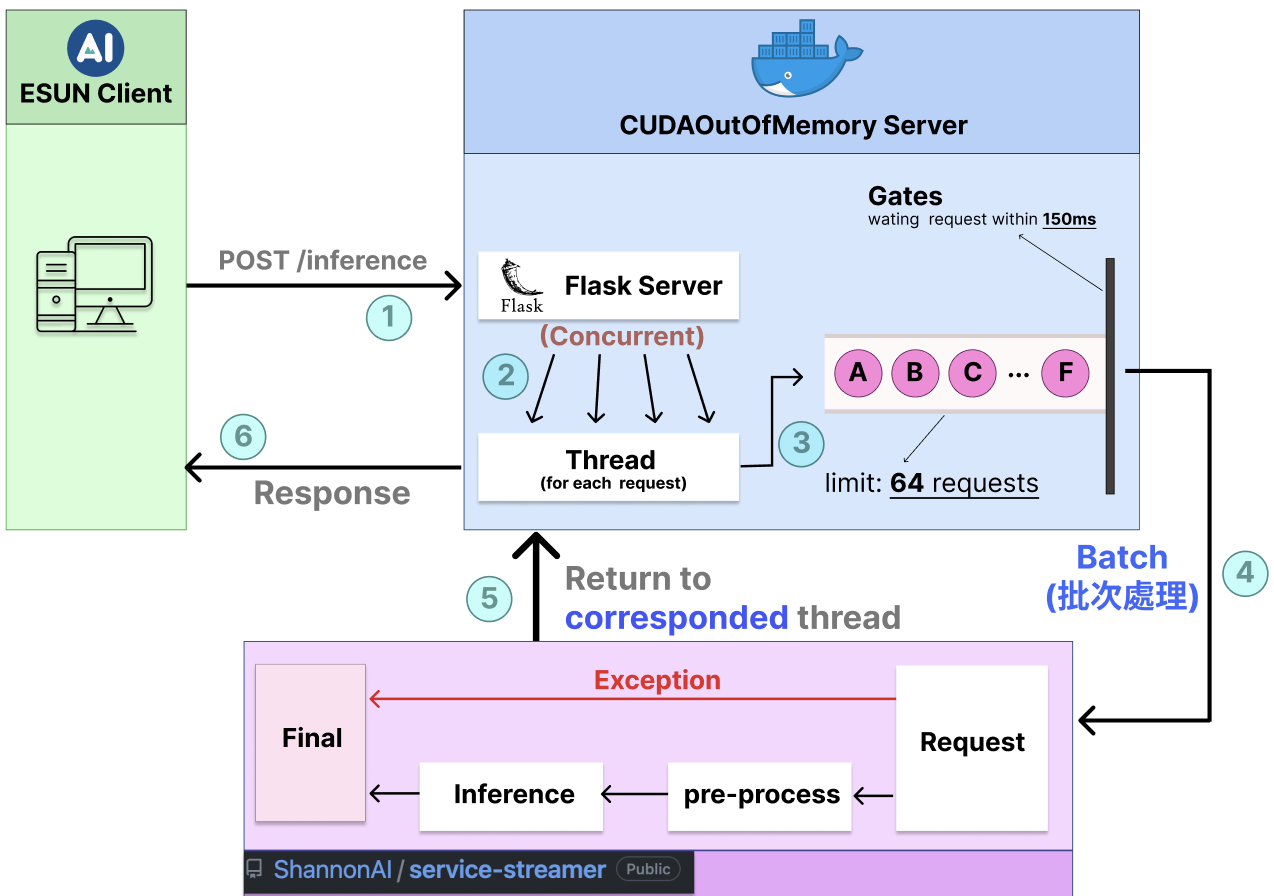
關於本隊的 API Server 是時候該做個總結了,以上是本隊的系統架構圖,流程大致如下:
- 玉山發出 POST Request
- Flask Server 為每個 Request 各創建一個 Thread 處理之
- 蒐集 150 毫秒以內的 Request,最大容量為 64 筆
- 每 150 毫秒 或超出容量上限,即 批次處理 (Batch)
- 對於每筆 Request,檢查與判定,若符合規格就跑 Model,否則直接吐回 TOP1 的語句內容。這邊回傳給 Request 對應的 Thread
- 回傳結果給玉山的伺服器
賽後檢討
流程大致上並無問題,也蠻順暢的。事後重新省視賽況和程式碼,認為以下幾點仍可改良:
- nvidia-docker: 運作時,有一段流程會不斷地查詢網路上的特定資源,以致於效率拖沓。因此,可以追蹤整體執行流程,將那些資源送進本機端維護並且定期更新,以本機端形式查閱,能提高約略三成的效能。
- multi-GPUs:由微軟公開的 ZeRO & DeepSpeed 加速技術,能夠將 NLP 模型龐大的參數攤分在若干個 GPU 上,能夠有效提升效能。
- Redis:是一種 Key-Value 的資料儲存形式,能夠高速查詢資料。因此我們能將超時的 Request 計算結果與唯一的任務代碼對應,那麼若再次重新發送就能夠接力計算,節省已逝去的時間。而本次使用的 service-streamer 工具中有提供 Redis 以 batch 方式加速的功能。
- Processes:常言「雞蛋不能放在同個籃子裡」,若以單個 Process 組織整套系統,當該筆 Process 出了狀況,將葬送整個服務。而以本次系統架構而論,即為單筆 Process 再分割出若干個 Thread 執行不同任務,因此日後得多在 multi-process 和 排程這塊琢磨,並需更加留意「例外」的處理形式。
- 程式碼維護:本次設定檔以及參數等工具不夠全面,只做了一半,如 Config 檔在 api 程式碼中就沒有使用,ArgumentParser 參數工具反倒是常更改的參數沒有寫進去。另一方面,由於程式碼撰寫頗為急促,故無暇顧及 “clean code”,這些都是未來可以改進的方向。
插曲——大災難
競賽有若干個階段,亦有兩梯次的測試賽以及正式賽。測試賽為期三天,在指定期間內每日晚間六點,準時轟炸你各位參賽者,一共四千題,完全比照正式賽之規格。而正式賽與測試賽唯一不同的在於連續日期從三天變為四天。
自詡為奴隸 (也許他並沒這樣說XD) 的實驗室電腦,很僥倖地在兩次測試賽長達六天內並未出任何狀況,盡心盡力地為我們付出,並穩定地繳交出兩萬四千題的答案。
然而同學間戲弄改編的名言:「關鍵時刻比衰小!」總是剎那間恍惚一瞬發生…正式賽第三天—我最忙碌的一天…發生了事故。當天早上,實驗室電腦們接一連二地發生狀況,或許是被攻擊,我們家的是自行關機,但這一重開機 CUDA 就出問題了,使得 GPU 1080 Ti 絲毫無用武之地…
左右觀察法—每個人都知曉的祕技,據聞是在考試時左看看、右看看就能獲取答案。而我使出了忍術「上下觀察法」,非常單純,如白雪般皎潔無瑕。僅僅是觀察位於自己前後兩支隊伍,前面 (第五名) 差距不小,而後面 (第七名) 也有著不容忽視的鴻溝,權衡之下,假設第三、第四天已 “baseline” 成績作結,綜合前兩天平均可以穩妥地取得第六名,那麼維持 “baseline” 採取最安全穩定的做法就萬事休矣了!
不久,迅速完成一個「無腦」服務,能夠在連線瞬間將 Request 內容列表第一句話吐回去,啊!真是完美!最終憑藉這樣穩定的服務度過比賽的下半餘生,並達成了領獎資格要求「低於 baseliine」之成績,以第六名作收,可喜可賀。
其實從這次事件中,可以學到兩件事:
一、不要太有自信
切忌,勿對服務的穩定性太有信心,必須戒慎恐懼好好關切他!本地端終究是有風險,除了遇到意外而終止程序外,當然還有「不可抗力」類型的機器罷工!上雲與地端都有各自的好處,但若能發展「監控」服務主動通知,並且有緊急應對的方式,才能應對服務的各種狀況。
二、「爛」方法其實很好
“Baseline” 什麼都不做—站在比賽以及服務的立場上,是相當切實的手法。比賽力求成效,而在已知能夠穩定獲取名次的狀況下,穩,再求精進才是上策,而勿追求卓越而功虧一簣,十分可惜。
服務依然以穩定為優先,而若全掛相當於 P0 事件,盡可能讓損失降低才是上策,因此若能夠緊急恢復出一個堪用版本,就幾乎只寫了一大半。能夠在緊急且資源有限的狀況下,盡可能地權衡局勢,致力於降低損失,會是提供服務時最重要的事情。
如何做得更好
這是我在賽後不斷思索的一件事,而從不同隊伍的做法中,領悟到幾件事情…
一、看清資料的本質
從官方給的六萬筆訓練資料中,若仔細觀察可以注意到有不少類似於新聞標題的語句:「行政院擬發放五倍券」,但也有很生活化的語句:「我想進行匯兌服務」。因此資料本身可以分成兩種取向:一般、新聞,並且很顯然的糾正這兩種不同類型的語句,應無法以相同的邏輯去糾正他。
除了語料源頭的分類以外,從測試資料本身亦可以做出不少變化。如同:「近年來股市迭宕不停」這樣的語句,從相似詞上看,「股市」或許容易被辨認為「不是」,每個語句會有多種相似詞彙,經過語音辨識後所辨識之語句,最有可能是「音對字不對」的狀況。
因此,我們可以建立「相似字詞典」,將單筆測資利用相似字詞典排列組合,塑造出更多測試資料。合理地推估六萬筆資料可擴增五倍、六倍以上,用以訓練模型的話,更可再進一步下降 1% 上下的 CER。
二、快,還要更快!
有很多加速技巧是沒碰過、聽過就不會知曉的,例如:微軟公開的 ONNX Runtime 是以 ONNX 格式儲存,能以其技術加速五倍以上的推理速度。亦或是攤分參數的技術,一樣是微軟開發的 ZeRO 以及 DeepSpeed,能將現有資源最大的活化。若能夠再配合本隊本次使用的 Batch 技術,那麼甚至可以一秒內同時應付二十筆 Requests 是很可能的。
結語
本次賽事我們兩位涉世未深的 碩 0 好夥伴費盡了心力,用了許多技術,難能可貴的能在第一次參與這樣的比賽,就搶到很前面的名次,獲得獎項,這也很超乎我們的預期。
不僅如此,更驗證了過去一年實習絕非虛度,技術上有深度進展,軟實力亦是。奠定在此基礎上,熟悉了整個系統維運與加速的程序,也學習到更多技巧可以運用,相信下次會更得心應手!
這次比較可惜的就是整體上過於倉促,沒有看透資料本身,能達到的成效就會有所囿限,加速上也有很多手法可以併用,希望下次能有類似的比賽能夠參與,也期許未來能提供更穩定且快速的系統,在四處都留下我們的蹤跡吧!